BeeBot 자동매매 프로그램 개발 과정_2단계 데이터 정렬 및 분석
BeeBot 자동매매 프로그램 개발 과정_2단계 데이터 정렬 및 분석

티커(ticker) 및 캔들(candle)이 포함하는 데이터 종류
거래소에 웹소켓(websocket)을 연결하여 티커(ticker)와 캔들(candle) 정보를 가입하면 실시간으로 해당 데이터가 수신됩니다.
티커(ticker)는 거래 정보(호가, 체결가, 고가/저가, 거래량, 물량 등)
캔들(candle)은 일정 시간간격의 OHLCV(open, high, low, close, volume) 시가, 고가, 저가, 종가, 거래량 정보를 포함합니다.
자동매매 프로그램(bot)은 위 두 가지 정보를 실시간으로 수신하여 매매전략에 따라 수식화 후, 매매신호를 생성하는 과정을 거칩니다.
일단 비트겟(bitget) 거래소에서 수신한 데이터에서 티커(ticker)는 그대로 사용하면 될 것으로 보입니다.
반면에, 캔들(candle) 정보는 가입 시 500개 캔들의 스냅샷을 보내주고 그 이후로는 초당 2회 업데이트 정보를 보내줍니다.
그러나 매매전략이 정확한 캔들 정보를 바탕으로 매매신호를 생성하기 위해서는 캔들 정보의 실시간 업데이트가 필요합니다.
Rate Limit이란?
신호를 계산할 때마다 필요한 캔들(candle)의 스냅샷을 API에 요청하여 수신할 수 있지만 너무 많은 request를 보내게 되면 API가 요청을 거절합니다.
대부분의 거래소는 짧은 시간에 일정한 회수 이상의 API 요청이 발생하면 수신을 거절하며, 이를 rate limit이라고 합니다. 거래소 마다 제한 조건이 다릅니다.
자동매매 프로그램은 상장된 모든 코인에 대한 정보를 수신하며 매매신호를 탐지하기 때문에, rate limit의 제한을 받게 됩니다.
따라서 웹소켓(websocket) 연결 시 수신된 캔들의 스냅샷(snapshot)을 메모리에 저장하고 실시간 수신되는 캔들 업데이트 정보로 500개의 캔들 스냅샷을 현행화하는 방법을 사용할 것입니다.
단계별 코드 구현 방법
제가 사용하는 방법은 테스트주도개발(TDD Test Driven Development)입니다.
현재 마켓데이터가 실시간으로 웹소켓(websocket)을 통해 유입되고 있습니다. 거래소 SDK를 설치해서 Example 코드를 실행해 본 것입니다.
다음 단계로 필요한 것은 앞서 적었듯이, 자동매매 프로그램에서 매매전략이 사용할 데이터입니다.
웹소켓에서 유입되는 데이터를 raw data라고 한다면, 전략이 매매신호를 생성할 수 있도록 가공된 데이터가 필요합니다.
이는 500개 캔들이 실시간으로 업데이트 되고있는 데이터입니다. 이제 요구사항이 정리된 것입니다.
이제 해당 데이터가 컨테이너에 담겨있다고 가정하고, 그 컨테이너의 이름을 CoinData라고 가정합니다.
1. CoinData 가정
CoinData에게 “비트코인(BTC) 데이터 내놔!”라고 하면, 비트코인의 최신 캔들 500개가 나와야 합니다.
위 과정을 다음과 같이 코드로 구현할 수 있습니다.
package beebotimport “testing”func TestMarketData(t *testing.T) {coinData := CoinData{“BTCUSDT”: “fresh candlesticks of BTCUSDT”}got := coinData.Get(“BTCUSDT”)want := “fresh candlesticks of BTCUSDT”if got != want {t.Errorf(“got %v want %v”, got, want)}}
위 테스트를 실행시켜 보면 다음과 같이 나옵니다.
$ go test -run TestMarketData
# bitget/beebot [bitget/beebot.test]
./marketData_test.go:6:14: undefined: CoinData
FAIL bitget/beebot [build failed]
CoinData가 undefined 되어있다고 FAIL하네요.
CoinData가 있다고 가정하고 벌인 일이니까 이런 결과가 나오는 것이 당연합니다. 그렇다면 다음 해야할 작업이 무엇일까요?
2. CoinData 정의(define)
이제부터 작업은 매우 쉬워집니다. 이제는 키보드 입력도 귀찮고 인공지능(ChatGPT)한테 한번 시켜볼까요?
Q.

A.
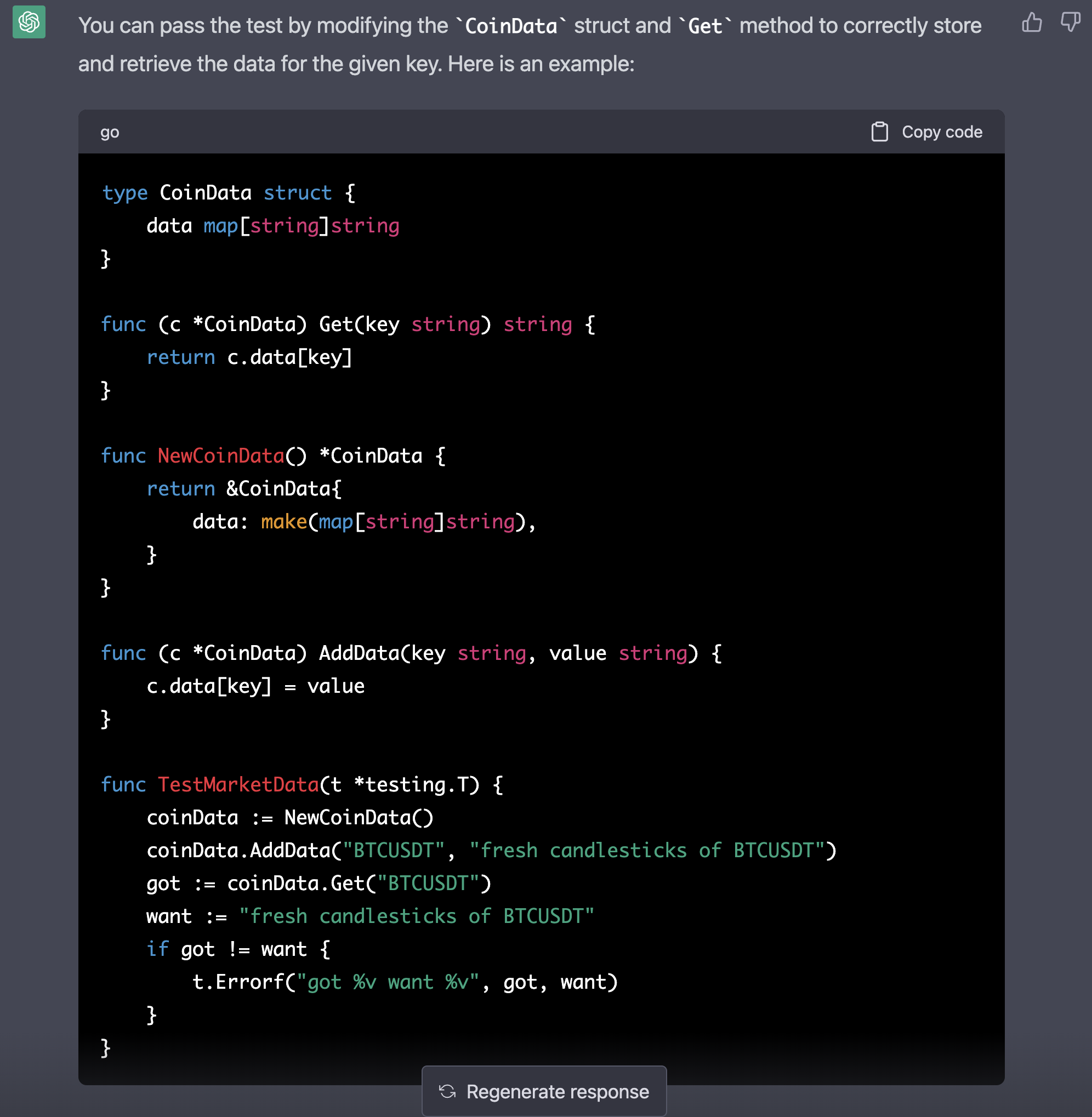
그냥 ctrl+c, ctrl+v 할 정도로 완벽합니다.
컨테이너에서 자료를 꺼내는 것 까지만 생각하고 테스트 코드를 만들었습니다. 그러나 인공지능이 컨테이너의 constructor와 자료를 담는 기능까지 생각해서 구현해 주었네요. 위 코드를 참고하여 다시 테스트를 run합니다.
CoinData의 type을 map[string]string으로 하는게 좋을까 아니면 인공이 만들어준대로 struct를 사용하면 좋을까?
작업을 더 진행하다 보면 알게되겠지요.
일단은 테스트 코드도 인공이 해준대로 수정하면 테스트는 통과됩니다. 뭔가 불편해지면 바꿉니다. 앞으로 벌어질 일을 미리 생각하고 바꾸는 건 게으른 개발자의 태도가 아닙니다.
3. 데이터를 CoinData struct에 담기
다음 단계는 우리의 raw data를 어떻게 이 CoinData에 담느냐 하는 문제를 해결하는 것이 되겠군요.
지금 해야하는 일이 무엇인지를 안다면 일 다 한거나 마찬가지입니다.
그걸 알아내기 위해서 테스트 코드를 작성하는 것입니다.
추가적으로 버그가 없는 깨끗한 코드,
이미 작성한 코드에 대해서 기억할 필요가 없는 코드,
그리고 언제든지 마음대로 코드를 수정할 수 있는 코드를 위해서 테스트 코드를 작성하는 것입니다.
테스트 코드를 작성하지 않는 개발자들은 할일을 다 알고있는 전지전능한 천재라고 필자는 생각합니다.
마무리하며…
이제는 테스트 코드만 짜면 인공지능 머슴이 알아서 코딩을 해주네요.
혼자서도 pair coding이 가능하다니, 천공카드로 코딩을 처음했던 사람으로서는 격세지감이네요.
막상 생각을 코드로 구현하려고 하면 막막한게 사실입니다.
물론 고수들은 전지적 시점에서 뚝딱뚝딱 만들어 낼 수 있겠지만, 개발이 초보인 경우는 한발짜도 떼지 못하고 헤매다 포기하는 경우가 많습니다.
누구나 처음이 없이 고수가 되는 길은 없겠지요.
머리가 좋고 시간이 많은 사람은 충분히 공부해서 전체 그림을 다 그리고 프로그래밍 언어를 충분히 배워서 스킬을 갖춘 다음에 구현하겠지만, 대부분의 경우는 그렇지 못합니다.
궁즉통이라 방법은 있습니다. 발자욱을 떼지 못한다면 기어가면 됩니다. 아주 조금씩 기다 보면 걷게 됩니다.
그런데 기어 보지도 않고서, 걷고 뛰는 법을 가만히 앉은채로 공부하려면 세월이 많이 가고, 다 공부하고 나서도 막상 걸으려 하면 잘 안됩니다. 프로그래밍 언어도 언어인지라, 연습없이는 잘 할 수 없습니다. 수많은 실수를 하면서 연습에 연습을 거듭해야 말을 할 수있게 되지요.
그렇다면 아무것도 모르고 어떻게 시작할까요?
약간의 용기와 무대포 정신만 있으면 됩니다. 먼저 이러저러한 기능을 하는 오브젝트가 있다고 가정하고 일단 들이댑니다.
이러저라한 기능을 하는 오브젝트가 있다는 것을 구체화하는 작업이 요구사항을 정리하는 것에 해당하겠지요.
요구사항을 정리한다니까 걱정스러운가요? 대강하면 됩니다. 틀리면 고치면 되니까요. 일단 들이대는 무대포 정신이 먼저 필요합니다.
문제는 지금 단계에서 필요한 것이 무엇인가가 확실히 정해진다면 구현은 다 된거나 마찬가지입니다. 그것을 정하는 방법은 일단 해보는 겁니다. 해봐야지만 뭐가 잘못된건지 발견하게 되니까요. 그런데 뭘 어떻게 해보란건가요?
초보자라도 용기를 내서 들이대 보시기 바라면서 이만….
✔️ 함께 보면 좋은 글
멋져요
진심?
CoinData는 함수가 아니고 struct 입니다.
그리고 rate limit은 제목을 달 만큼 중요하진 않습니다.